
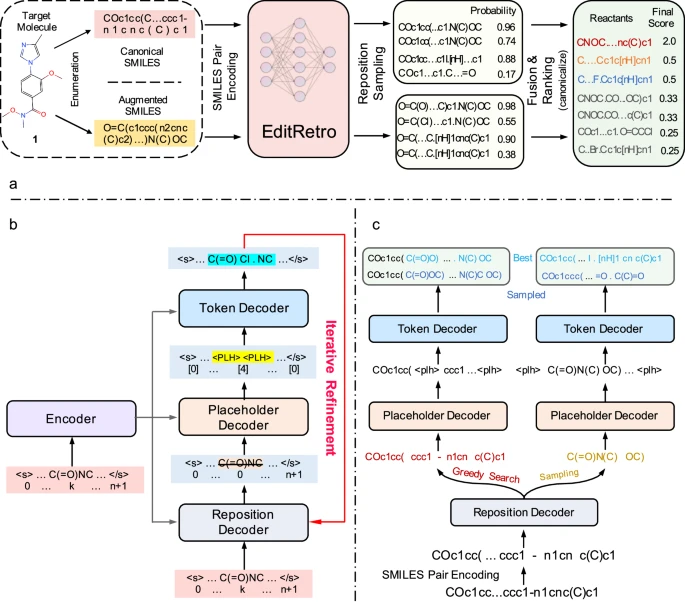
逆向合成是药物发现和有机合成中的一项关键任务,人工智能(AI)越来越多地被用来加快这一过程。然而,现有的方法采用逐个令牌的解码方法将目标分子串转换为相应的前体,表现出不甚理想的性能和有限的多样性。由于化学反应通常会引起局部分子变化,反应物和产物通常会明显重叠。鉴于此,来自浙江大学的Huajun Chen,Tingjun Hou和Qiang Zhang等人提出将单步逆向合成预测重新定义为分子串编辑任务,迭代地细化目标分子串以生成前体化合物。
文章要点:
1) 该研究开发的这种方法涉及一种基于片段的生成编辑模型,该模型使用显式的序列编辑操作,并且,该研究设计了一个具有重新定位采样和序列增强的推理模块,以提高预测精度和多样性;
2) 此外,研究还通过大量实验证明,这一模型生成了高质量和多样化的结果,在标准基准数据集USPTO-50 K上实现了60.8%的top-1准确率,取得了卓越的性能。
参考资料:
Han, Y., Xu, X., Hsieh, CY. et al. Retrosynthesis prediction with an iterative string editing model. Nat Commun 15, 6404 (2024).
10.1038/s41467-024-50617-1
https://doi.org/10.1038/s41467-024-50617-1

















